Intro to Data Lake, Delta Lake and Iceberg
My recent focus has been on data warehouse design and helping organizations extract value from their data. Given the recent news surrounding Iceberg, I wanted to spend a little time exploring the open source table formats.
There is a lot of news recently, but I'm sharing two links that highlight how the data landscape is evolving. Databricks, the company generally associated with Delta Lake, just bought Tabular, a company founded by the creators of Iceberg. Snowflake, the company best known for separating compute and (proprietary) storage, now supports Iceberg, the open table format.
Overview
Let's start with a quick overview of just what we are talking about. All of these terms can be a bit overwhelming; what's the difference between a Data Lake and a Delta Lake? Are Delta Live Tables also open source like Delta Tables? Let's take a moment to go over some of these terms/concepts.
Data Lake
The easiest way to think about a data lake is that it's scalable and non-proprietary storage for your org's structured, semi-structured and unstructured data. Examples can include structured data stored as parquet files, raw JSON generated by product analytics SDKs and images used for training ML models. This is the data that usually powers your org's Business Intelligence and AI efforts.
Lakehouse Architecture
Some of the earliest data lakes utilized cloud storage such as S3. While this is a scalable and cost effective way to store data, it is missing a lot of features. This is where Lakehouse Architecture comes in.
A lakehouse is a new, open architecture that combines the best elements of data lakes and data warehouses.
The lakehouse uses open source compute engines like Spark or Presto and provides features such as ACID transactions and schema enforcement.
In essence, we can store our data on cloud storage, while still having access to features found in a database management system. We get the best of both the worlds - cheap storage for big data with the speed, scalability and reliability that we come to expect with databases.
Medallion Architecture
A medallion architecture is a data design pattern used to logically organize data in a lakehouse, with the goal of incrementally and progressively improving the structure and quality of data as it flows through each layer of the architecture (from Bronze ⇒ Silver ⇒ Gold layer tables).
While the name is new, for anyone who has previously done data warehouse design, the concepts will be very familiar. Using an imperfect analogy, this is similar to Raw ⇒ Staging ⇒ Star/Snowflake schema layer tables.
Open Table Formats
Open table formats offer a layer of abstraction over data lakes and they are what enable the benefits and features of data lake architecture. As the name suggests, these formats allow for the abstraction of multiple data files as a single dataset, i.e. a table. These tables can be queried using popular tools and languages, e.g. SQL.
Hive was one of the earlier formats, followed more recently by Apache Hudi, Apache Iceberg and Delta Lake.
Features include:
- ACID transactions
- Partition evolution
- Time travel
Delta Lake
Delta Lake is an open source storage layer that implements the features mentioned above for data lakes. Perhaps the name may suggest otherwise, but it is an implementation of a Data Lake, not an alternative. It also provides features such as time travel and secure data sharing with other organizations. The most common implementations of Delta Lake are a commercial offering by Databricks and or an open source implementation using Spark.
I also want to mention that the Databricks implementation includes Delta Live Tables, which is an ingestion/ETL platform. The name Delta Live Tables can create some confusion because, while it uses Delta Lake, it is not a part of open source Delta Lake. [Not a spokesperson for Databricks, so take all this with a grain of salt.]
Iceberg
Iceberg is another, more recent, open source table format that is similar to Delta Lake. Iceberg also offers time travel, rollback, schema evolution and SQL compatibility. It is gaining in popularity each day and it's unknown right now which implementation will emerge as the dominant one. One of the reasons Iceberg is so popular is that it is implementation/vendor agnostic, whereas Delta Lake is mostly associated with Databricks. All this makes the Databricks acquisition of Tabular very interesting and it will be interesting to see where this leads
Catalog
After a while, one doesn't think about it, but all database management systems have a catalog. In Postgres, this is the Information Schema. This catalog has information about tables, schemas, users, permissions, etc. and is used by the compute engine. Similarly, if our data lake in S3 stores our data, we need to know the schema structure, permissions, etc. of that data. The catalog is a vital piece of the Lakehouse Architecture.
Note: This should not be confused with a new category of tools in the Modern Data Stack. Data Catalogs like Atlan, Monte Carlo, Castor, etc. are more for end users than the data lake compute engine.
Implementation
All these data lake architecture features are great, but how does one utilize an open table format for their org? There's a few different pieces that are needed for implementation.
The three pieces that are crucial are:
- Storage
- Compute
- Catalog
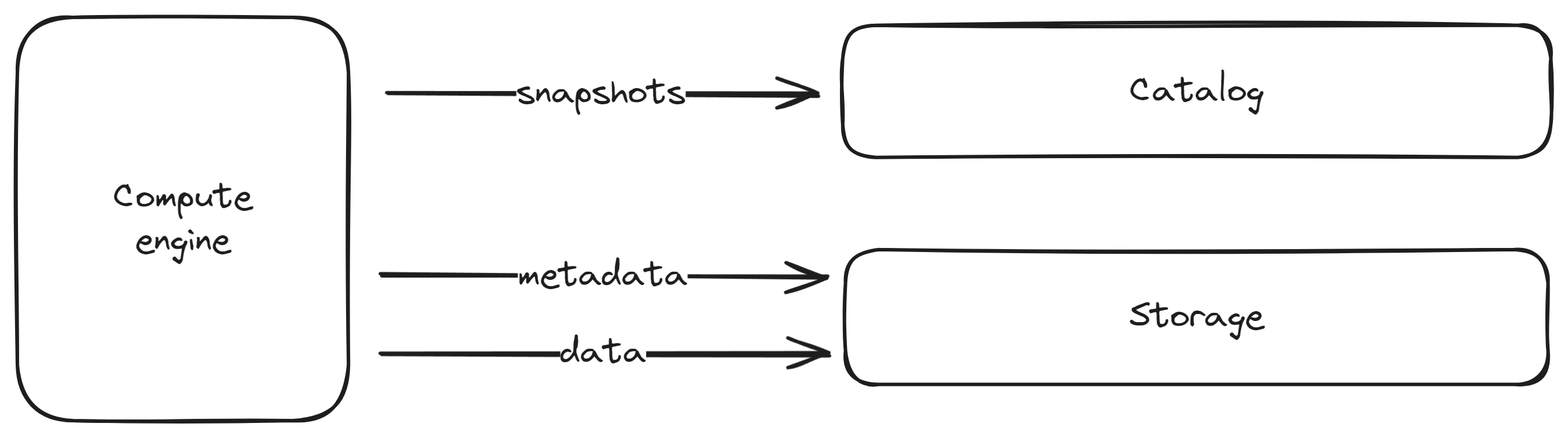
Storage
We need a place to store our data. Since we are implementing Lakehouse Architecture, we should pick storage that is scalable and cost efficient. Unless we are implementing storage ourselves, S3/GCS is a good choice.
Compute engine
We need some way to read/write to our Iceberg tables. Spark is probably the most common execution engine.
Catalog
Finally, we will have multiple tables/schemas and it's important to be able to keep track of these objects. A catalog will help us do that.
Getting started
It would be a lot of work to implement these core components ourselves. Thankfully, there are existing implementations that one can use.
The list is ever growing and a lot of existing tools are integrating the Iceberg table format each day. However, some of the implementations are read-only and are meant to help integrate existing Iceberg tables into an existing proprietary system, i.e. one can query, but can't write. The focus of this post is on pure implementations, i.e. where one can read/write.
Iceberg
Dremio is a native implementation of Iceberg, from the creators of Apache Arrow. The product includes Project Nessie, an open source data lake catalog and offers a free, fully-managed lakehouse platform that uses your cloud infrastructure. One can choose Dremio's query engine, Spark or Flink. Dremio also integrates with dbt and many BI tools.
Delta Lake
Databricks was an early, commercial implementation of Delta Lake. Built on top of Delta Lake, the Databricks platform brings together many aspects of an ETL/ELT system such as orchestration, CI/CD, etc. The implementation includes Delta Live Tables and Unity Catalog, that Databricks made open source recently.
Modern Data Stack
How do Iceberg and data lake architecture fit in with the rest of the Modern Data Stack? Although the open table formats are still somewhat greenfield, it's not difficult to see data lake architecture becoming the standard going forward. It is scalable and cost efficient, has all the features of a data warehouse (plus more) and was created with ML in mind. Best of all, Iceberg provides an open source and vendor agnostic implementation of an open table format.
With additional vendors adopting Iceberg and the entire data stack being compatible with Iceberg, there isn't a reason data lake architecture won't be the standard going forward.
Next steps
I will try to follow up with more detailed tutorials for these and other implementations.