ETL Postgres to Redshift using SQL and Foreign Data Wrappers
In this post, I'll be going over how to ETL Postgres data into Redshift using minimal code and no infrastructure other than our source (RDS Postgres) and target (Redshift) databases. We will be using Foreign Data Wrappers and SQL to achieve this. Here is the high level solution we will be implementing:
- Ensure we have the appropriate extension and user created on our source database.
- Create an external schema on Redshift that points to Postgres
- Use SQL to materialize, i.e. ETL the data, into Redshift
Background
I would like to get data from our microservices into a data store for reporting. These microservices are using AWS Postgres RDS as the backend database. Ideally, the data would be up-to-date more frequently than daily. What are some good solutions? Athena? AWS DMS?
This is a question someone asked in a semi-public forum recently. Upon digging a bit deeper, I learned that the combined size of all the microservice databases is around 100GB.
Some of the responses to the question included:
- Debezium
- Flink
- Kafka
- Paid third-party ETL solutions
To summarize, here is the situation:
- Relatively small data set
- AWS RDS Postgres is the source.
While there are many other solutions that I would consider, given these constraints and given the goal of quickly delivering value to the stakeholders in a scalable manner, my suggestion was to use Foreign Data Wrappers to ETL the data into Redshift.
Other Solutions
A natural question to ask is why not implement other solutions like CDC and streaming? Others may ask why not use a different data store like Snowflake?
These are good questions and the simple answer is bandwidth and implementation time.
If your org already has CDC set up for your microservice databases and already implements streaming solutions, then Yes, you should definitely consider those.
If you have time to negotiate a contract with Snowflake, it is certainly a good option. By contrast, if you are already an AWS shop, getting started with Redshift takes a few minutes and there is no need to go through a sales cycle. It's a scalable solution to take one from 100GB to a few hundred TBs easily, perhaps even further.
As an outsider looking in, my experience tells me that the aforementioned org probably does not have the resources to implement the previously discussed alternative implementations.
Postgres (as a data warehouse) is the only solution I would not recommend because it is not scalable for an analytics workload; as you add more users, more tools and varied queries/workloads, you will definitely run into major issues, like queries being blocked and/or performance issues.
Implementation
Let's continue with our suggested implementation.
First, let's connect to our (source) Postgres database and make sure that we have the foreign data wrappers extension installed. Run the following SQL (after updating to a better password) on your source/microservice database.
-- If the extension does not exist, create it
CREATE EXTENSION IF NOT EXISTS postgres_fdw;
-- Confirm the extension has been created
SELECT extname FROM pg_extension;
-- We also need a user with the appropriate privileges
-- I will be giving broader (read-only) access, but one can
-- limit this as needed.
CREATE ROLE fdw_user
PASSWORD 'S0meth1ngSecure'
NOSUPERUSER
NOCREATEDB
NOCREATEROLE
INHERIT
LOGIN;
-- Grant privileges for this user to access the data
GRANT SELECT ON ALL TABLES IN SCHEMA public to fdw_user;We will now create external schemas on Redshift to connect to our Postgres instance.
CREATE EXTERNAL SCHEMA microservice1_fdw
FROM POSTGRES
-- Database name and schema
DATABASE '<your database>' SCHEMA '<your schema>'
-- The host name and port of the database
URI '<database hostname or ip>' PORT 5432
-- A secret with the username/password used to connect to Postgres.
SECRET_ARN '<arn of your secret>'
-- A secret with the username/password used to connect to Postgres.
IAM_ROLE '<arn of redshift role>';
-- Query the newly created external schema
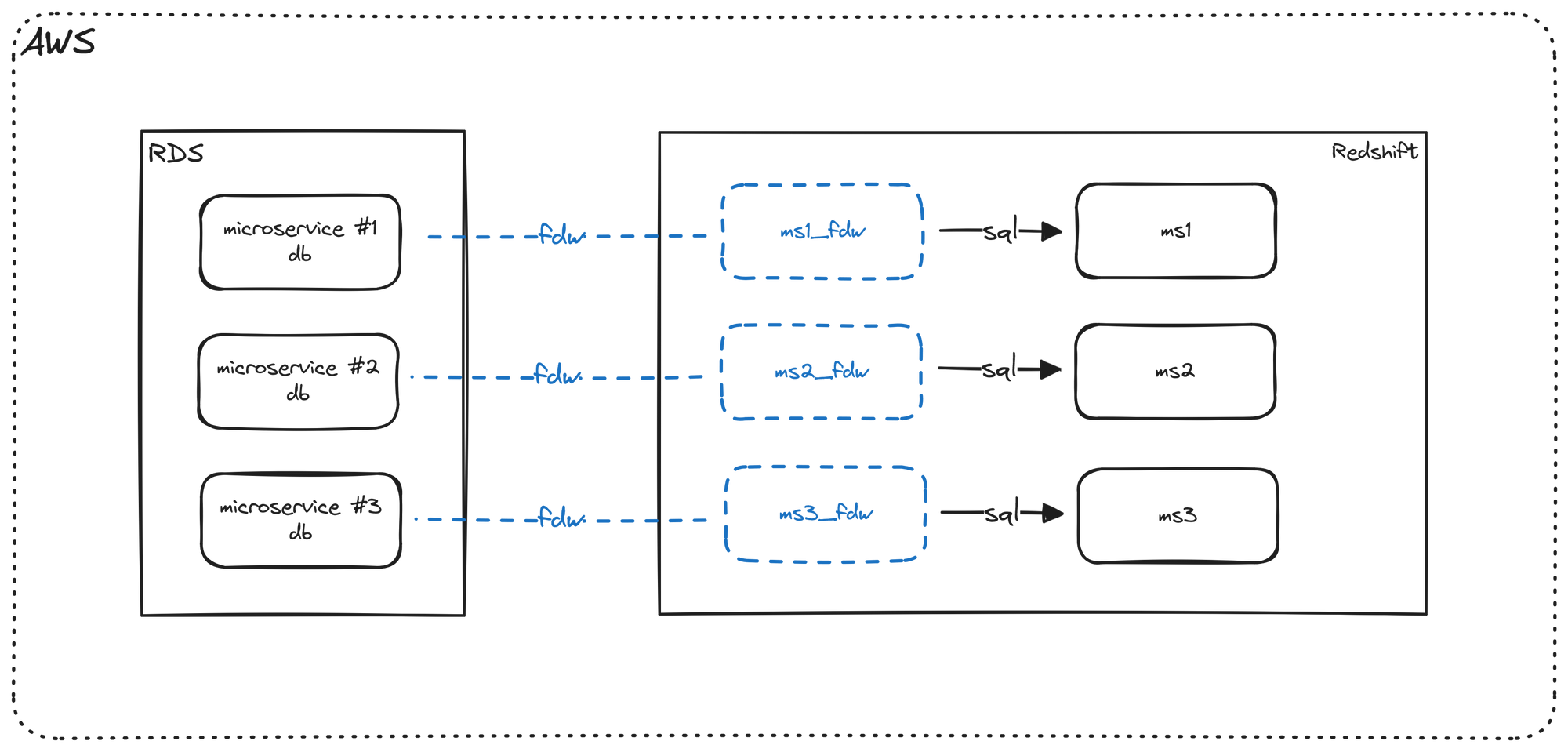
select * from dev.microservice1_fdw.users;From an architecture point of view, this is where we are right now.
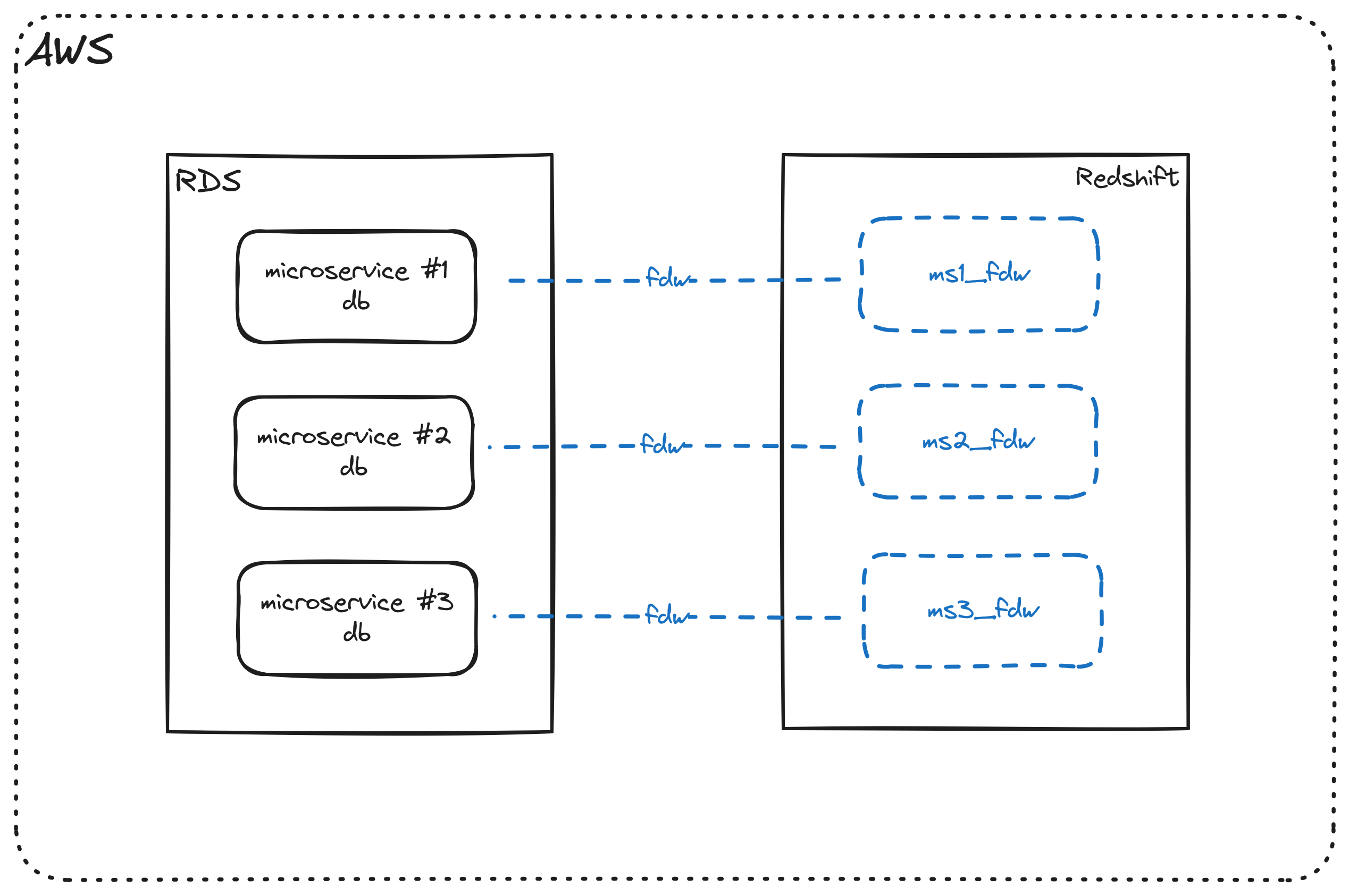
We have our Postgres microservice databases on the left and Redshift on the right. Using Foreign Data Wrappers (FDW), we created external schemas in Redshift that point to our Postgres databases.
At this point:
- We will have access to the latest data.
- However, currently, the data is not materialized in Redshift. Consequently, any queries queries submitted to the Redshift external schema(s) will be passed on to Postgres and will ultimately be executed on Postgres.
The goal is to take advantage of the features of Redshift, so let's go ahead and materialize the data in Redshift
-- Create a schema in Redshift
CREATE SCHEMA microservice1;
-- Materialize the data in Redshift by creating a local table.
-- Data moves from Postgres to Redshift in this step.
CREATE TABLE dev.microservice1.users as
select
*
from dev.microservice1_fdw.users;
-- Verify the data was copied successfully by
-- querying the local Redshift table
select * from dev.microservice1.users;We have completed the pipeline and our architecture diagram looks like this.
Let's add another row to our microservice database. We can run the same query as before, but this is a bad ETL pattern especially as our data volume grows. Let's update our query to retrieve only the new records.
-- Get the last ETL date and retrieve records added/updated after that date.
INSERT into dev.microservice1.users
select
*
from dev.microservice1_fdw.users
where last_mod_dt > (select max(last_mod_dt) from dev.microservice1.users)
;We can now schedule this query to run every hour, every day or whatever our desired refresh cadence may be.
Here is a video showing the entire process
Start building without a lot of infrastructure
A lot of orgs start their Data journey by creating a replica of the prod database and using that replica for analysis. This may work well when there's a couple of people running ad-hoc queries. However, once one adds a BI tool and the team grows, this solution is not scalable at all, even at a few hundred GBs of data.
However, by landing this data into our data warehouse instead, we can start to build a scalable analytics environment that can be used by the business to make informed decisions. We can pull data from our production (application/microservice) databases and start implementing data quality from the start. As the team grows and best practices are put in place, we can continue to scale without issues.
By taking advantage of foreign data wrappers, the only tool/infrastructure we need is the databases themselves. We don't need to pay extra for a cloud ETL tool like FiveTran or Stitchdata, we don't need to deploy open source solutions like Meltano or Airbyte and we don't need to waste internal resources building a custom ETL tool.
Next steps
As the video shows, adding additional tables, or even schemas and additional microservice databases, to Redshift is fairly easy and straightforward.
This is a basic demonstration of how we can ETL data from our production Postgres to Redshift. There are many ways to improve this pipeline and some suggestions that come to mind include:
- Since our ETL is SQL based, we can use
dbt. Note: This was a quick demo, but for production, we may want to refine and modify our SQL. - Using a scheduler to execute our pipeline (Airflow, Dagster, Prefect, etc.)
- Schema alerts to notify us when upstream schemas/tables/columns change.