dbt for data pipelines using foreign data wrappers
Background
In a previous post, I talked about utilizing foreign data wrappers to move data between our production database (application/microservice) and our data warehouse. The high level architecture diagram looked something like this.
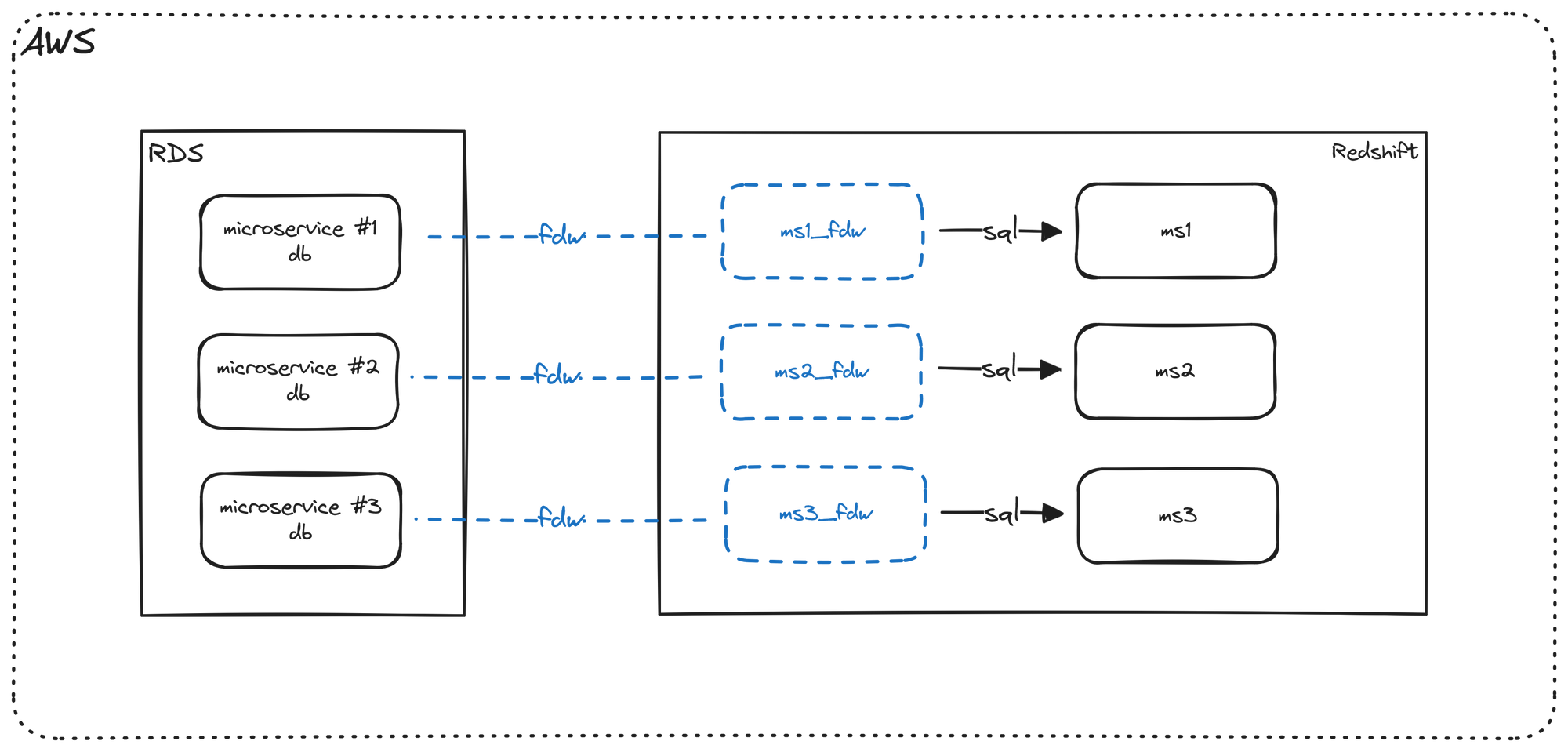
We are now going to add dbt to our pipeline. Please note that there are many benefits to using dbt, and while I give a small preview below, I talk about that in a different post, so those topics won't be covered in great detail here.
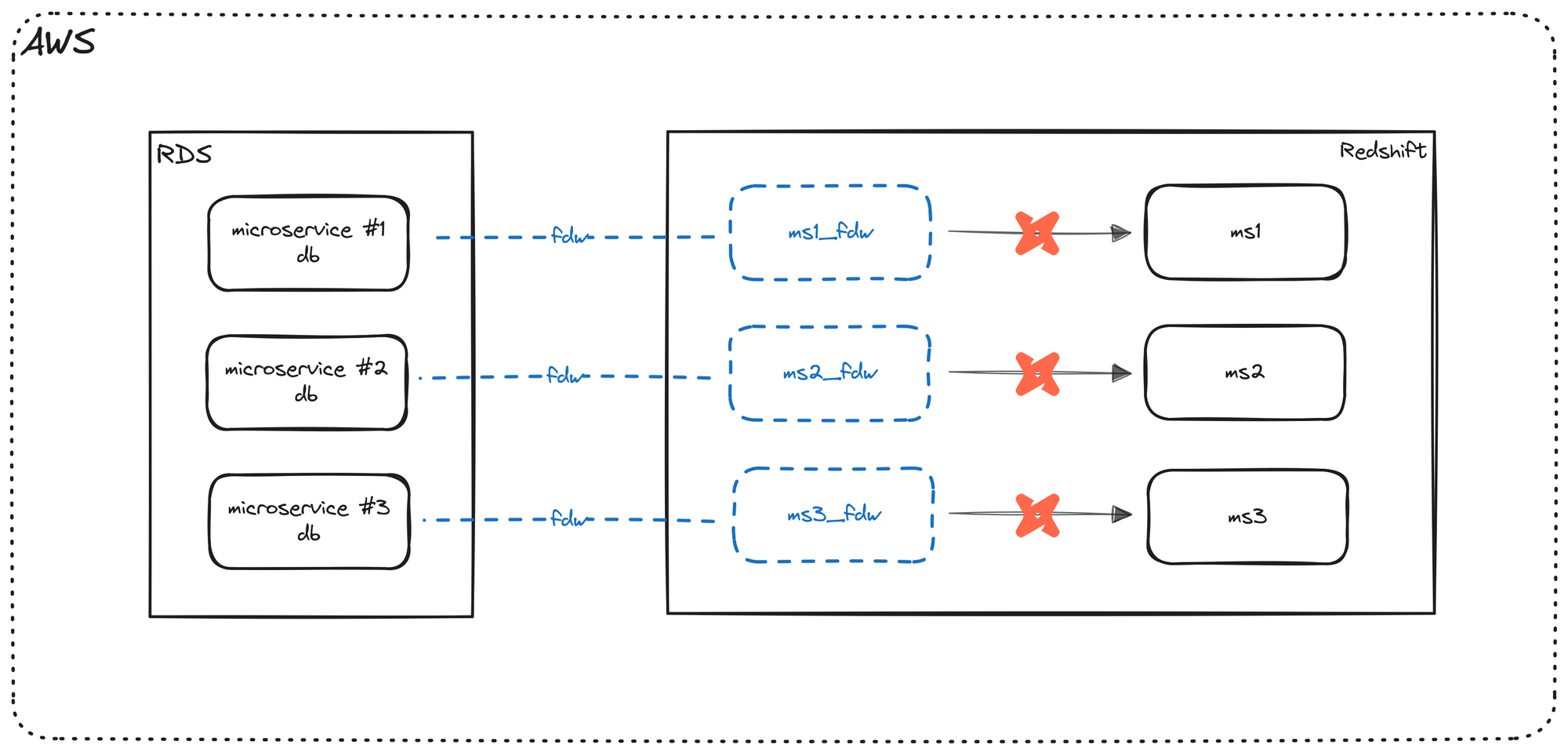
Implementation
Let's start by creating a source. For folks who have used dbt previously, the following code should look familiar.
version: 2
sources:
- name: app_blog
schema: microservice01_fdw
tables:
- name: blog_readersLet's take a moment to discuss what's going on here. We give this source a name of our choosing, in this case app_blog. This is the name we will use in the rest of the dbt code base. We also specify the Redshift database schema that it points to; this should be the external schema that points to Postgres, microservice01_fdw in our case. Finally, we list the tables in the source that we want to include in our pipeline. I've only added one table for now, but this would likely have most, if not all, the tables in our schema.
To reiterate, our source is the external schema we created, that points to Postgres. (As a reminder, this external schema in Redshift has the latest Postgres data available in real time). As you may be aware, dbt is a tool used for the T portion of an ELT pipeline and dbt can only point to one database at a time. Normally a Postgres to Redshift pipeline could not be implemented with dbt because we are using two different databases. However, because our external schema exists within Redshift, which is also our data warehouse, we can most certainly utilize dbt for our pipeline.
Let's create a dbt model file.
with source as (
select
id
, user_name
, create_dt
, last_mod_dt
from {{ source('app_blog', 'blog_readers') }}
),
renamed as (
select
*
from source
)
select * from renamed
As you can see, it's pretty straightforward and we're still only using SQL (with some Jinja). For those folks who have not used dbt, the main thing to note is the FROM clause in our initial CTE. We are referencing the source that we added above. We're selecting all the columns from our table, without any transformation, and we get a one-to-one copy of the data into our warehouse.
Finally, as part of dbt best practices, we should have a corresponding yaml file for our dbt model. It would look something like this:
version: 2
models:
- name: blog_readers
columns:
- name: id
tests:
- not_null
- unique
- name: user_name
tests:
- not_null
- name: create_dt
- name: last_mod_dtAt this point, we are ready to use dbt to move data. For dbt Core, we would simply need to run the following command:
# dbt build will run the models and tests
dbt build
# OR more simply, run the following
dbt run
dbt testIt's fairly straightforward, but some things worth noting are:
- We are implementing some basic tests (checking for nulls and uniqueness)
- While not required, we specify all columns explicitly.
As your data warehouse (and your Data team) grows, these best practices will prove invaluable.
Next steps
As the two posts have shown, we can start implementing a data warehouse without needing a lot of infrastructure and without spending a lot of time / resources. It requires mostly a few SQL statements and setting up dbt.
Up until now, our pipeline has been fairly manual. We can add an orchestration tool like Airflow, Dagster, Prefect, etc. to schedule our data refreshes so that we can automate our pipeline.