Data Contracts using dbt and foreign data wrappers
I wrote earlier about building data pipelines using foreign data wrappers.
Some of the benefits include:
- Development costs: You don't need any additional infrastructure or developer resources since this is a SQL based pipeline.
- Velocity: This goes hand in hand with cost. Since less resources are needed, a stable, reliable pipeline can be spun up fairly quickly.
Today, I will be highlighting another great benefit of using a foreign data wrapper based pipeline by discussing Data Contracts in dbt.
Challenge
Pipelines can break when upstream tables are modified. While this is not ideal, an even worse outcome is inaccurate metrics and KPIs. This is where data contracts can help.
Simply put, a data contract is an agreement between a data producer and their consumers that defines how data is structured, formatted, and validated.
Foreign data wrappers
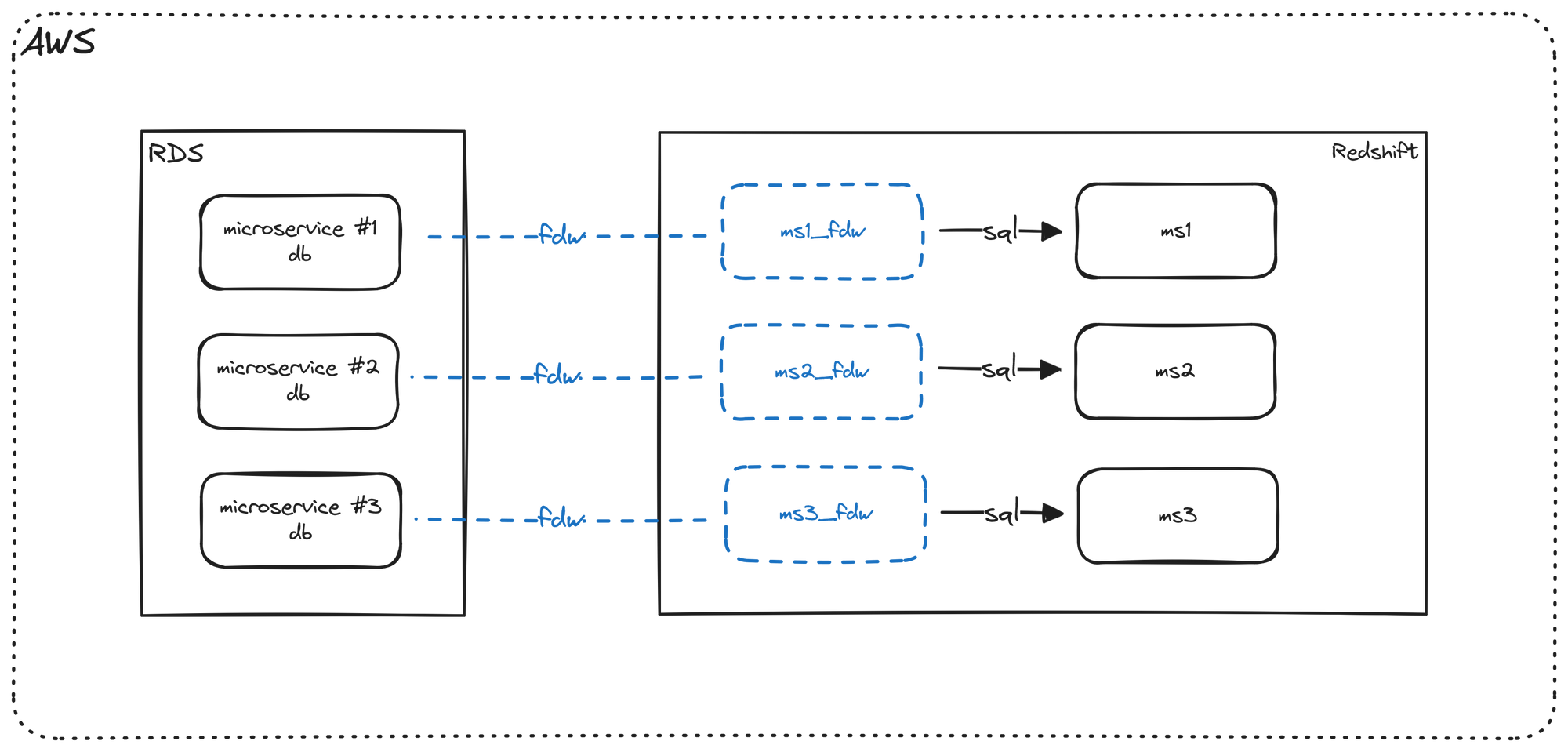
As a quick reminder, foreign data wrappers allow us to have pointers to our application/microservice database tables in our data warehouse. Since our tables reside in our data warehouse, this overcomes dbt's limitation of having the same connection for both source and target, consequently allowing us to implement contracts on our application database.
Example implementation
# customers_fdw.yml
models:
- name: customers_fdw
# specify that this model has a contract
config:
contract:
enforced: true
# define contract/columns
columns:
- name: customer_id
data_type: int
- name: customer_name
data_type: stringThis is a simple contract on our customers_fdw table which specifies that the customer_id column is an integer and the customer_name column is a string. Tomorrow, if an application developer updated the customer_id column to use a cuid, this would stop our model from running.
Since we have specified a contract, we know immediately what the issue is and how to resolve it. We no longer have to waste time trying to identify the root cause of the failure.
Empowering collaboration
Yaml is a widely used specification and it is easy to read. Most application developers are familiar with yaml. If we gave our application developers read-only access to our dbt repo, they could see what contracts we have specified.
Furthermore, if we published our dbt lineage graph within the org, the application developers could not only see how their changes may impact tables downstream, but also what reports and metrics would be affected (using dbt Exposures).
We could also grant application developers update privileges on our dbt repo, so they could update the contracts themselves, while also informing the Data team by opening a PR. However, I don't recommend this since downstream teams need to be given advance warning of upcoming changes and this should be done during the development phase.
Conclusion
If you have been building your pipeline using foreign data wrappers, not only have you been able to quickly implement stable and performant pipelines, but you have also started implementing data ops best practices such as Data Contracts.
For smaller orgs that do not have petabyte scale data, I highly recommend this approach.